
오라클
1. Column을 Row 형태로 바꾸는 방법
UNPIVOT 오라클 함수 사용
- 11g 이상만 사용 가능
- 빠른 속도로 대용량 데이터를 처리할 때 용이하다.
-- 테스트를 위한 테이블, 데이터 쿼리
CREATE TABLE sale_stats(
id INT PRIMARY KEY,
fiscal_year INT,
product_a INT,
product_b INT,
product_c INT
);
INSERT INTO sale_stats(id, fiscal_year, product_a, product_b, product_c)
VALUES(1,2017, NULL, 200, 300);
INSERT INTO sale_stats(id, fiscal_year, product_a, product_b, product_c)
VALUES(2,2018, 150, NULL, 250);
INSERT INTO sale_stats(id, fiscal_year, product_a, product_b, product_c)
VALUES(3,2019, 150, 220, NULL);
- 형태
SELECT *
FROM ( 피벗 대상 쿼리문 )
UNPIVOT [INCLUDE | EXCLUDE NULLS] (
컬럼별칭(값)
FOR 컬럼별칭(열)
IN (피벗열명 AS '별칭', ... )
)
기본적으로 unpivot은 null 값을 제외한 데이터를 출력하지만, INCLUDE | EXCLUDE NULLS절을 사용하면 null 값 행을 포함하거나 제외할 수 있다.
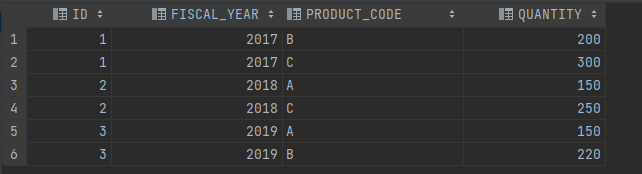
- 예시쿼리
select * from SALE_STATS
unpivot (
quantity
for product_code
in(
PRODUCT_A as 'A',
PRODUCT_B as 'B',
PRODUCT_C as 'C'
)
)
- 결과
+여러열을 unpivot할 경우
DROP TABLE sale_stats;
CREATE TABLE sale_stats (
id INT PRIMARY KEY,
fiscal_year INT,
a_qty INT,
a_value DEC(19,2),
b_qty INT,
b_value DEC(19,2)
);
INSERT INTO sale_stats(id, fiscal_year, a_qty, a_value, b_qty, b_value)
VALUES(1, 2018, 100, 1000, 2000, 4000);
INSERT INTO sale_stats(id, fiscal_year, a_qty, a_value, b_qty, b_value)
VALUES(2, 2019, 150, 1500, 2500, 5000);
- 여러열을 unpivot 하는 쿼리
SELECT * FROM sale_stats
UNPIVOT (
(quantity, amount)
FOR product_code
IN (
(a_qty, a_value) AS 'A',
(b_qty, b_value) AS 'B'
)
);
- 결과

2)union all, 테이블 복제 사용
- union all은 동일 테이블에 4번 접근하여 처리한다. SQL 속도는 가장 좋지 않으므로 몇 천건 이하로만 사용하는 것을 권장한다.
2. Row를 Column 형태로 바꾸는 방법
예제를 위한 테이블 쿼리
-- auto-generated definition
create table EMP
(
EMPNO VARCHAR2(100) not null,
ENAME VARCHAR2(100) not null,
JOB VARCHAR2(100) not null,
MGR VARCHAR2(100) default NULL,
HIREDATE DATE default NULL,
SAL VARCHAR2(100) default NULL,
COMM VARCHAR2(100) default NULL,
DEPTNO VARCHAR2(100) default NULL
)
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7369', 'SMITH', 'CLERK', '7902', TIMESTAMP '1980-12-17 00:00:00.000000', '800', '0', '20');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7499', 'ALLEN', 'SALESMAN', '7698', TIMESTAMP '1981-02-20 00:00:00.000000', '1600', '300', '30');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7521', 'WARD', 'SALESMAN', '7698', TIMESTAMP '1981-02-22 00:00:00.000000', '1250', '500', '30');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7566', 'JONES', 'MANAGER', '7839', TIMESTAMP '1981-04-02 00:00:00.000000', '2975', '0', '20');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7566', 'JONES', 'MANAGER', '7839', TIMESTAMP '1980-12-17 00:00:00.000000', '2975', '0', '20');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7698', 'BLAKE', 'MANAGER', '7839', TIMESTAMP '1981-05-01 00:00:00.000000', '2850', '0', '30');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7654', 'MARTIN', 'SALESMAN', '7698', TIMESTAMP '1981-09-28 00:00:00.000000', '1250', '1400', '30');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7782', 'CLARK', 'MANAGER', '7839', TIMESTAMP '1981-06-09 00:00:00.000000', '2450', '0', '10');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7788', 'SCOTT', 'ANALYST', '7566', TIMESTAMP '1987-04-19 00:00:00.000000', '3000', '0', '20');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7839', 'KING', 'PRESIDENT', NULL, TIMESTAMP '1981-11-17 00:00:00.000000', '5000', '0', '10');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7844', 'TURNER', 'SALESMAN', '7698', TIMESTAMP '1981-09-08 00:00:00.000000', '1500', '0', '30');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7876', 'ADAMS', 'CLERK', '7788', TIMESTAMP '1987-05-23 00:00:00.000000', '1100', '0', '20');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7900', 'JAMES', 'CLERK', '7698', TIMESTAMP '1981-12-03 00:00:00.000000', '950', '0', '30');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7902', 'FORD', 'ANALYST', '7566', TIMESTAMP '1981-12-03 00:00:00.000000', '3000', '0', '20');
INSERT INTO EMP
(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
VALUES('7934', 'MILLER', 'CLERK', '7782', TIMESTAMP '1982-01-23 00:00:00.000000', '1300', '0', '10');- 형태
SELECT
select_list
FROM
table_name
PIVOT (
pivot_clause
pivot_for_clause
pivot_in_clause
);
- pivot_clause : 집계할 열을 지정.
- pivot_for_clause : 그룹화하거나 피벗할 열을 지정.
- pivot_in_clause : 열에 대한 필터를 정의합니다
- 예시 쿼리 - JOB컬럼의 row들을 컬럼으로 부서별 연봉 평균을 낸다.
SELECT * FROM(
SELECT DEPTNO, JOB, SAL FROM EMP
)PIVOT(AVG(SAL) FOR JOB IN
('ANALYST', 'CLERK','MANAGER','PRESIDENT','SALESMAN')
)ORDER BY DEPTNO;
- 결과

mariaDB
1. Row 형태의 테이터를 Column으로 바꾸는 방법
Oracle이나 SQL Server 같은 데이터베이스 서버에서는 PIVOT함수를 사용할 수 있으나, MariaDB는 PIVOT 함수가 없으므로 동일한 작업 수행을 위해서는 CASE문을 사용하여 행을 열로 회전하는 select 쿼리를 작성해야한다.
--학생
CREATE TABLE students (
id INT PRIMARY KEY,
name varchar(50) NOT NULL,
department VARCHAR(15) NOT NULL);
--과목
CREATE TABLE courses (
course_id VARCHAR(20) PRIMARY KEY,
name varchar(50) NOT NULL,
credit SMALLINT NOT NULL);
-- 시험결과
CREATE TABLE result(
std_id INT NOT NULL,
course_id VARCHAR(20) NOT NULL,
mark_type VARCHAR(20) NOT NULL,
marks SMALLINT NOT NULL,
FOREIGN KEY (std_id) REFERENCES students(id),
FOREIGN KEY (course_id) REFERENCES courses(course_id),
PRIMARY KEY (std_id, course_id, mark_type));
INSERT INTO students VALUES
( '1937463', 'Harper Lee', 'CSE'),
( '1937464', 'Garcia Marquez', 'CSE'),
( '1937465', 'Forster, E.M.', 'CSE'),
( '1937466', 'Ralph Ellison', 'CSE');
INSERT INTO courses VALUES
( 'CSE-401', 'Object Oriented programming', 3),
( 'CSE-403', 'Data Structure', 2),
( 'CSE-407', 'Unix programming', 2);
INSERT INTO result VALUES
( '1937463', 'CSE-401','Internal Exam' ,15),
( '1937463', 'CSE-401','Mid Term Exam' ,20),
( '1937463', 'CSE-401','Final Exam', 35),
( '1937464', 'CSE-403','Internal Exam' ,17),
( '1937464', 'CSE-403','Mid Term Exam' ,15),
( '1937464', 'CSE-403','Final Exam', 30),
( '1937465', 'CSE-401','Internal Exam' ,18),
( '1937465', 'CSE-401','Mid Term Exam' ,23),
( '1937465', 'CSE-401','Final Exam', 38),
( '1937466', 'CSE-407','Internal Exam' ,20),
( '1937466', 'CSE-407','Mid Term Exam' ,22),
( '1937466', 'CSE-407','Final Exam', 40);
시험결과 테이블은 다음과 같고, mark_type의 row를 컬럼으로 학생들의 과목별 점수를 뽑고자 한다.
- 실행쿼리
SELECT result.std_id, result.course_id,
MAX(CASE WHEN result.mark_type = "Internal Exam" THEN result.marks END) "Internal Exam",
MAX(CASE WHEN result.mark_type = "Mid Term Exam" THEN result.marks END) "Mid Term Exam",
MAX(CASE WHEN result.mark_type = "Final Exam" THEN result.marks END) "Final Exam"
FROM result
GROUP BY result.std_id, result.course_id
ORDER BY result.std_id, result.course_id ASC;
- 결과

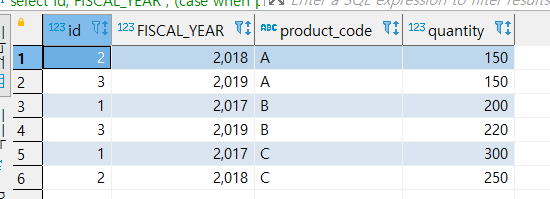
2. Column 형태의 테이터를 Row로 바꾸는 방법
UNPIVOT 함수가 따로 없기 때문에, case 문과 union all 이 필요하다. (성능이 떨어지므로 주의)
- 실행쿼리
select id, FISCAL_YEAR ,
(case when product_a is not null then 'A' else '' end) product_code, product_a as quantity from sale_stats where product_a is not null
union all
select id, FISCAL_YEAR ,
(case when product_b is not null then 'B' else '' end) product_code, product_b as product_code from sale_stats where product_b is not null
union all
select id, FISCAL_YEAR ,
(case when product_c is not null then 'C' else '' end) product_code, product_c as product_code from sale_stats where product_c is not null
- 결과
참고 블로그 및 사이트)
[Oracle] 오라클 PIVOT(피벗) 함수 사용법 (행을 열로 변환, 피봇)
오라클 11g부터 PIVOT 기능을 제공합니다. 기존 이하버전에서는 DECODE 함수를 이용하여 로우를 컬럼으로 변경하는 작업을 하였습니다. PIVOT 기능을 이용하면 DECODE의 복잡하고 비직관적인 코드를 조
gent.tistory.com
https://www.oracletutorial.com/oracle-basics/oracle-unpivot/
Oracle UNPIVOT Explained By Practical Examples
In this tutorial, you will learn how to use the Oracle UNPIVOT clause to transpose columns to rows.
www.oracletutorial.com
https://linuxhint.com/mysql_pivot/
MySQL Pivot: rotating rows to columns
You have to create a database and some related tables where rows of one table will be converted into the columns like PIVOT() function. Run the following SQL statements to create a database named ‘unidb’ and create three tables named ‘students’,
linuxhint.com
'BACKEND > DB' 카테고리의 다른 글
| DB 최적화로 고급 개발자로 성장하기: 이직을 위한 기술 스택 확장 (4) | 2025.03.25 |
|---|---|
| 오라클 date 날짜 시간 비교 (0) | 2023.09.07 |